- Published on
Re: Implementation [02]: GPT + Mixture of Experts (MoE)
- Authors

- Name
- Shuqi Wang
Re: Implementation Series — Episode 02
Building upon our basic GPT, we now implement a Sparse Mixture of Experts (MoE) architecture. This allows us to scale up model capacity (parameters) without proportionally increasing computational cost (FLOPs) during inference.
Overview
In a standard Transformer, every token passes through the same Feed-Forward Network (FFN). In an MoE model, we replace the FFN with a set of "experts" (multiple FFNs) and a "router" (gate).
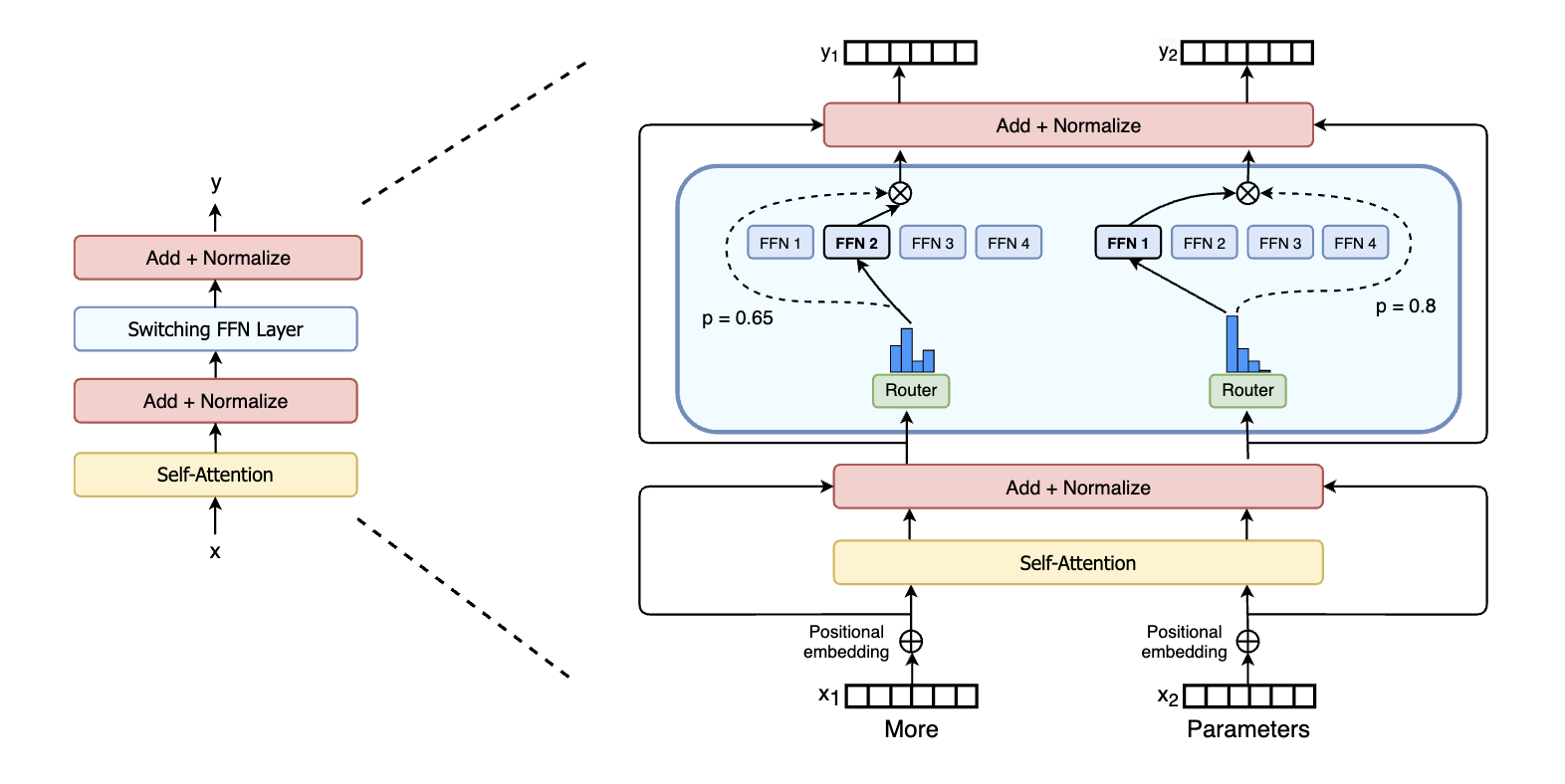
For each token, the router selects the top-k most relevant experts. Only those experts process the token. This sparsity means we can have a huge number of parameters (many experts) but only use a small fraction of them per token.
Section 1: Hyperparameters & Data Loading
import torch
import torch.nn as nn
from torch.nn import functional as F
# ==================== Hyperparameters ====================
batch_size = 16
block_size = 32
max_iters = 5000
eval_interval = 100
learning_rate = 1e-3
device = 'cuda' if torch.cuda.is_available() else 'cpu'
eval_iters = 200
n_embd = 64
n_head = 4
n_layer = 4
dropout = 0.0
# --- MoE Specific Hyperparameters ---
num_experts = 4 # Number of experts per layer
top_k = 2 # Number of active experts per token
torch.manual_seed(1337)
# ==================== Data Loading ====================
# (Same as Episode 01)
with open('input.txt', 'r', encoding='utf-8') as f:
text = f.read()
chars = sorted(list(set(text)))
vocab_size = len(chars)
stoi = {ch: i for i, ch in enumerate(chars)}
itos = {i: ch for i, ch in enumerate(chars)}
encode = lambda s: [stoi[c] for c in s]
decode = lambda l: ''.join([itos[i] for i in l])
data = torch.tensor(encode(text), dtype=torch.long)
n = int(0.9 * len(data))
train_data = data[:n]
val_data = data[n:]
def get_batch(split):
data = train_data if split == 'train' else val_data
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([data[i:i + block_size] for i in ix])
y = torch.stack([data[i + 1:i + block_size + 1] for i in ix])
x, y = x.to(device), y.to(device)
return x, y
@torch.no_grad()
def estimate_loss():
out = {}
model.eval()
for split in ['train', 'val']:
losses = torch.zeros(eval_iters)
for k in range(eval_iters):
X, Y = get_batch(split)
logits, loss, aux_loss = model(X, Y) # Expect 3 return values now
losses[k] = loss.item()
out[split] = losses.mean()
model.train()
return out
Section 2: Standard Components (Attention & FFN)
We reuse the Attention mechanism from [01]. The FeedForwardNetwork will now serve as a single "Expert".
class AttentionHead(nn.Module):
"""Single head of self-attention (Same as Ep.01)"""
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
B, T, C = x.shape
k = self.key(x)
q = self.query(x)
v = self.value(x)
wei = q @ k.transpose(-2, -1) * (C ** -0.5)
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
wei = self.dropout(wei)
out = wei @ v
return out
class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([AttentionHead(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(n_embd, n_embd)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out
class FeedForwardNetwork(nn.Module):
"""This will now act as a single EXPERT."""
def __init__(self, n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd),
nn.ReLU(),
nn.Linear(4 * n_embd, n_embd),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
Section 3: The Gating Mechanism (Router)
Goal: We need a smart "traffic controller" that examines each token and decides which experts are best suited to process it.
The Challenge of "Collapse": If we simply route tokens to the expert with the highest score (greedy routing), the model might fall into a degenerate state where it sends everything to just one or two experts (who get better and better), while the rest starve and never learn. This is called expert collapse.
The Solution: Noisy Top-k Gating: To prevent collapse and encourage exploration, we add tunable Gaussian noise to the router's logits before making a decision. This randomness forces the model to try different experts during training, ensuring a balanced load.
Implementation: We implement NoisyTopkRouter, which:
- Computes routing logits for all experts (
topk_route_linear). - Computes a noise level for each expert (
noise_linear). - Adds noise to logits and selects the top-k experts.
- Returns the gating weights (softmax) and the indices of the selected experts.
class NoisyTopkRouter(nn.Module):
"""
Predicts expert weights and adds noise to perform 'Noisy Top-k Gating'.
This router helps with load balancing by adding stochasticity, encouraging the model
to utilize all experts rather than collapsing onto a few.
"""
def __init__(self, n_embd, num_experts, top_k):
super().__init__()
self.top_k = top_k
# Two linear layers: one for the routing logits, one for the noise magnitude
self.topk_route_linear = nn.Linear(n_embd, num_experts)
self.noise_linear = nn.Linear(n_embd, num_experts)
def forward(self, x):
# x shape: (Batch, Time, n_embd)
# 1. Compute the raw routing logits
logits = self.topk_route_linear(x)
# 2. Compute the noise magnitude (softplus ensures it's positive)
noise_logits = self.noise_linear(x)
noise_std = F.softplus(noise_logits)
# 3. Add noise: Standard Normal * Learned Std Dev
noise = torch.randn_like(logits) * noise_std
noisy_logits = logits + noise
# 4. Select Top-k experts
# indices: Which experts were selected (B, T, top_k)
top_k_logits, indices = noisy_logits.topk(self.top_k, dim=-1)
# 5. Calculate Gating Weights (Softmax)
# We create a sparse tensor where only top-k indices have values, others are -inf
zeros = torch.full_like(noisy_logits, float('-inf'))
sparse_logits = zeros.scatter(-1, indices, top_k_logits)
# Softmax over all experts (unselected ones become 0)
router_output = F.softmax(sparse_logits, dim=-1)
return router_output, indices
Section 4: Sparse Mixture of Experts (MoE) Layer
Goal: Scale the model's capacity (number of parameters) without significantly increasing the computational cost per token (FLOPs).
Mechanism: "Conditional Computation": Instead of one massive FFN processed by every token, we have a collection of num_experts smaller FFNs. For every token, we run:
Where is the gate weight from our router, and is the output of the -th expert.
The "Auxiliary Loss": To further enforce load balancing, we calculate an auxiliary loss that penalizes the model if it disproportionately favors certain experts over a batch. We aim to minimize the variation in expert usage.
class MoE(nn.Module):
"""
A Sparse Mixture of Experts layer that replaces the standard Feed-Forward Network.
"""
def __init__(self, n_embd, num_experts, top_k):
super().__init__()
self.router = NoisyTopkRouter(n_embd, num_experts, top_k)
# Create a list of 'Experts' (each is a standard FFN)
self.experts = nn.ModuleList([FeedForwardNetwork(n_embd) for _ in range(num_experts)])
self.top_k = top_k
def forward(self, x):
# 1. Routing: Get weights and selected expert indices
gating_output, indices = self.router(x)
final_output = torch.zeros_like(x)
# Flatten batch and time dimensions for efficient processing
flat_x = x.view(-1, x.shape[-1])
flat_gating_output = gating_output.view(-1, gating_output.shape[-1])
flat_indices = indices.view(-1, indices.shape[-1])
# 2. Sparse Execution
# We process each expert one by one
for i, expert in enumerate(self.experts):
# Check which tokens selected this expert 'i'
expert_mask = (flat_indices == i).any(dim=-1)
flat_indices_for_expert = torch.nonzero(expert_mask).squeeze(-1)
# If this expert has work to do:
if flat_indices_for_expert.numel() > 0:
expert_input = flat_x[flat_indices_for_expert]
expert_output = expert(expert_input)
# Weight the output by the gating score
# We fetch the specific weight assigned to expert 'i' for these tokens
gating_scores = flat_gating_output[flat_indices_for_expert, i].unsqueeze(-1)
weighted_output = expert_output * gating_scores
# Accumulate results into final output
final_output.view(-1, x.shape[-1]).index_add_(0, flat_indices_for_expert, weighted_output)
# 3. Auxiliary Loss Calculation (Load Balancing)
# We want to minimize the coefficient of variation of the load
# aux_loss = alpha * N * sum(f_i * P_i)
# P_i: Fraction of router probability mass allocated to expert i
gates = gating_output.view(-1, len(self.experts))
importance = gates.sum(0)
# f_i: Fraction of tokens routed to expert i
flattened_indices = indices.view(-1)
load = torch.bincount(flattened_indices, minlength=len(self.experts)).float()
# Normalize
importance = importance / (gates.size(0))
load = load / (gates.size(0) * self.top_k)
# The loss encourages importance and load to be uniform
aux_loss = (importance * load).sum() * len(self.experts)
return final_output, aux_loss
Section 5: Updating the Transformer Block
Goal: Integrate the MoE layer into the standard Transformer architecture.
The Update: We replace the standard FeedForwardNetwork with our new MoE layer. Because the MoE layer returns an auxiliary loss (for load balancing), our block's forward method must now return this loss as well, so it can be propagated up to the main training loop.
Structure:
- Multi-Head Attention (Unchanged)
- Add & Norm
- Mixture of Experts (Replaces FFN)
- Add & Norm
class TransformerBlock(nn.Module):
"""
A standard Transformer block, but with the FFN replaced by a sparse MoE layer.
"""
def __init__(self, n_embd, n_head):
super().__init__()
head_size = n_embd // n_head
self.attention = MultiHeadAttention(n_head, head_size)
# Replaced standard FFN with MoE
self.moe = MoE(n_embd, num_experts, top_k)
self.ln1 = nn.LayerNorm(n_embd)
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
# 1. Attention Sub-layer (Standard)
x = x + self.attention(self.ln1(x))
# 2. MoE Sub-layer
# Note: We receive aux_loss from the MoE layer
moe_out, aux_loss = self.moe(self.ln2(x))
x = x + moe_out
return x, aux_loss
Section 6: DecoderOnlyGPT
class DecoderOnlyGPT(nn.Module):
def __init__(self):
super().__init__()
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
self.position_embedding_table = nn.Embedding(block_size, n_embd)
# Using ModuleList so we can iterate explicitly to collect losses
self.blocks = nn.ModuleList([TransformerBlock(n_embd, n_head=n_head) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embd)
self.lm_head = nn.Linear(n_embd, vocab_size)
def forward(self, idx, targets=None):
B, T = idx.shape
tok_emb = self.token_embedding_table(idx)
pos_emb = self.position_embedding_table(torch.arange(T, device=device))
x = tok_emb + pos_emb
# Iterate blocks and accumulate aux_loss
total_aux_loss = 0.0
for block in self.blocks:
x, aux_loss = block(x)
total_aux_loss += aux_loss
x = self.ln_f(x)
logits = self.lm_head(x)
loss = None
if targets is not None:
B, T, C = logits.shape
logits = logits.view(B * T, C)
targets = targets.view(B * T)
# Main Task Loss
loss = F.cross_entropy(logits, targets)
# Add Load Balancing Loss (weighted little bit, e.g. 0.01)
loss += 0.01 * total_aux_loss
return logits, loss, total_aux_loss
def generate(self, idx, max_new_tokens):
for _ in range(max_new_tokens):
idx_cond = idx[:, -block_size:]
logits, _, _ = self(idx_cond)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
return idx
Section 7: Training Loop
The training loop remains mostly the same, as the loss modification is handled inside the model's forward pass.
model = DecoderOnlyGPT()
m = model.to(device)
# --- MoE Analysis: Active vs Total Parameters ---
# "MoE's Soul": It looks big (Total), but runs small (Active)
total_params = sum(p.numel() for p in m.parameters())
# Identify expert parameters vs shared parameters
expert_params = 0
for name, p in m.named_parameters():
if 'experts' in name:
expert_params += p.numel()
shared_params = total_params - expert_params
# Active parameters = Shared + (top_k / num_experts) * Expert_Total
active_expert_params = expert_params * (top_k / num_experts)
total_active_params = shared_params + active_expert_params
print(f"Total Parameters: {total_params/1e6:.2f}M (Storage Cost)")
print(f"Active Parameters: {total_active_params/1e6:.2f}M (Inference Cost)")
print(f"Sparsity Ratio: {total_active_params/total_params:.2%} (Active/Total)")
print("-" * 50)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
# Initialize aux_loss for the first logging step (before any forward pass)
aux_loss = torch.tensor(0.0, device=device)
for iter in range(max_iters):
if iter % eval_interval == 0 or iter == max_iters - 1:
losses = estimate_loss()
print(f"step {iter:4d}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}, aux loss {aux_loss.item():.6f}")
xb, yb = get_batch('train')
logits, loss, aux_loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# Generation Test
context = torch.zeros((1, 1), dtype=torch.long, device=device)
generated_text = m.generate(context, max_new_tokens=500)
print(decode(generated_text[0].tolist()))
Summary
In this notebook, we successfully transformed a standard dense GPT model into a Sparse Mixture of Experts (MoE) model. Let's recap the key milestones:
- Conditional Computation: By replacing the standard Feed-Forward Network with an MoE layer, we enabled the model to activate only a subset of its parameters for each token.
- Dynamic Routing: We implemented a
NoisyTopkRouterthat learns to dynamically assign tokens to the most relevant experts, using noise to ensure exploration and prevent collapse. - Load Balancing: We introduced an auxiliary loss to encourage the router to distribute work evenly across all experts, ensuring efficient utilization of the model's capacity.
The Result: A model that can scale to significantly more parameters (high capacity) while maintaining fixed inference costs (constant FLOPs per token). This architecture is the foundation behind modern giants like Mixtral 8x7B and GPT-4.
Recommended Reading & References
To dive deeper into the world of MoE, I recommend the following foundational papers:
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (Shazeer et al., 2017)
- The paper that reintroduced MoE to modern deep learning.
- Read on arXiv
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (Fedus et al., 2021)
- Introduced the simplified "Switch" routing mechanism (Top-1 routing).
- Read on arXiv
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (Lepikhin et al., 2020)
- Discusses scaling MoE across massive clusters.
- Read on arXiv
Mixtral of Experts (Jiang et al., 2024)
- The technical report for Mixtral 8x7B, a state-of-the-art open-weights MoE model.
- Read on arXiv